Crafting the Transformer: An Object-Oriented Approach
In this section, we’re going to construct a Transformer model from the ground up. Our methodology is inspired by the insights of Umar Jamil—be sure to check out his work for a deeper understanding.
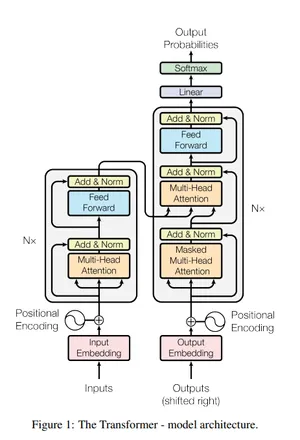
To bring the Transformer to life, we’ve broken down the development process into two primary segments: modeling and training. We’ll start with modeling, which is crucial to grasp before we proceed to the training phase. As a constant guide, we’ve placed an image of the Transformer architecture in the right corner of the page for your reference.
Within our model.py, we’ve crafted a robust framework composed of nine classes and one essential function. These components form the backbone of our implementation:
The function buildTransformer weaves these components together, initializing the architecture for our model.
Understanding the Architecture
In the forthcoming sections, we’ll dissect how each of these twelve classes contributes to a functioning Transformer model. It’s important to recognize the role of each component:
Classes: They represent distinct, well-defined parts of our model, encapsulating specific functionalities.
Object-Oriented Design: This paradigm ensures our code is modular, making it easier to understand, maintain, and extend.
By the end of this exploration, you’ll have a comprehensive understanding of the nuts and bolts of the Transformer model. Stay tuned as we delve into the intricacies of each class and function, paving the way towards a robust implementation.
Remember, the full codebase on GitHub will offer a more granular look at the inner workings of the model. This guide aims to provide a high-level understanding, ensuring you grasp the architectural decisions and algorithmic flow that define the Transformer.
d_model: int - The dimensionality of the embedding space. vocab_size: int - The size of the vocabulary of source language. Forward Method- Accepts input x and produces embeddings scaled by the square root of d_model, leading to an output size of (vocab_size, d_model).
Notes
The embedding layer weights are scaled by the square root of d_model as suggested in the original paper.
Positional Encoding
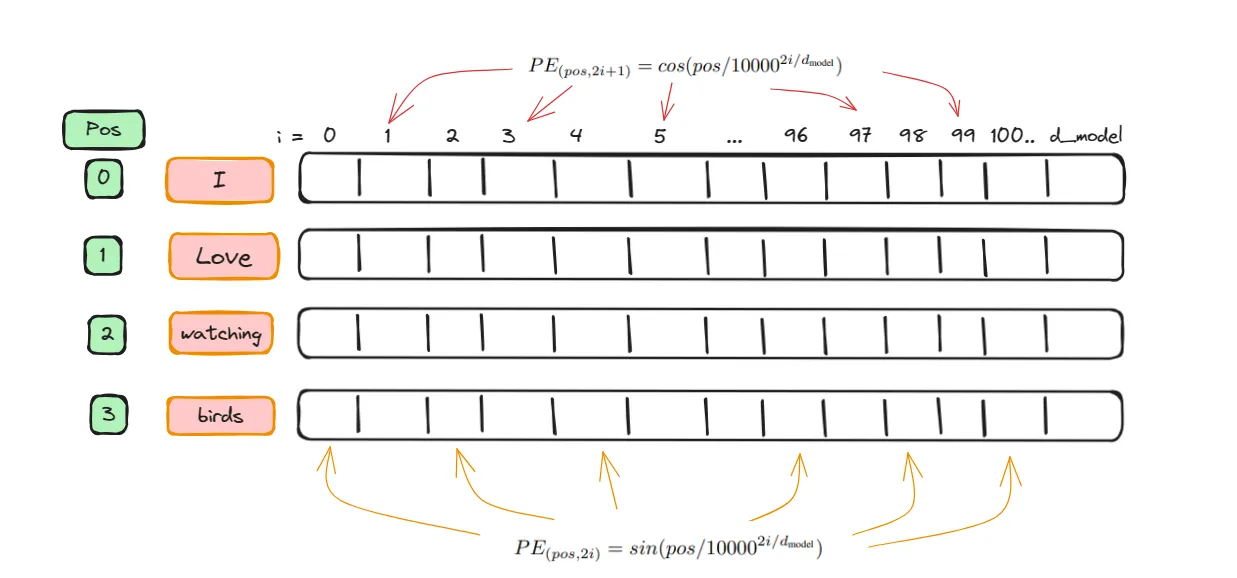
The PositionalEncoding is designed to provide each token in a sequence with a unique position encoding.
Consider this example:
In the sentence 'I love watching birds', the word 'I' is at position 0, and the word ‘birds’ is at position 3. Each word is converted into a vector representation with a dimension of d_model(This is from embeddings layer). Positional encoding adds positional information to each vector. This is achieved by using a ‘pos’ attribute, where the even positions in the vector receive a sine function value, and the odd positions receive a cosine function value, as illustrated below
classPositionalEncoding(nn.Module):
def__init__(self, d_model: int, seq_len: int , dropout: float) ->None:
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len,d_model)
#create a vector of shape (seq_len,1)
position = torch.arange(0,seq_len,dtype= torch.float).unsqueeze(1)
x = x+(self.pe[:,:x.shape[1],:]).requires_grad_(False) # (batch, seq_len, d_model)
returnself.dropout(x)
Constructor (__init__ method)
Initializes the positional encoding with the following parameters:
d_model (int): Represents the dimensionality of the embedding space.
seq_len (int): The maximum length of the sequence to be encoded.
dropout (float): The dropout rate for regularization.
Within the constructor:
A zero matrix pe of shape (seq_len, d_model) is created to store the positional encodings.
The position tensor is generated with values from 0 to seq_len-1 and reshaped by unsqueeze(1) to have a shape of (seq_len, 1). This function is used to add a dimension, making matrix operations possible.
div_term calculates a divisor used in the alternating sine and cosine functions based on the model’s dimension and a fixed constant (10000.0). The exp and arange functions create values for this divisor.
Sine is applied to even indices in the positional encoding matrix, while cosine is applied to odd indices. This alternation provides a unique pattern for each position.
The unsqueeze(0) is used on pe to add a batch dimension, making it compatible with the expected input dimensions.
Register Buffer
The register_buffer method is used to create a persistent, non-learnable buffer for the positional encoding tensor pe. This buffer is not a parameter of the model and will not be updated during training, but it will be part of the model’s state, allowing for easy saving and loading.
Forward Method (forward method)
In the forward pass, the input x is added to the positional encodings, ensuring that each token’s position is considered.
The positional encodings up to x.shape[1] (the sequence length of the batch) are used, and requires_grad_ is set to False to indicate that no gradient should be computed.
Finally, dropout is applied to the resulting tensor.
Important Points:
The output tensor maintains the shape (batch, seq_len, d_model), adhering to the expected input dimensions for subsequent layers.
Keeping track of tensor shapes at each operation is a crucial practice for debugging. It helps ensure the consistency of tensor operations and can prevent shape mismatches, which are common sources of errors.
The module’s design, which includes sinusoidal patterns and a non-learnable buffer, is a deliberate choice to provide the model with an effective way to interpret token positions without increasing the number of trainable parameters.
Debugging Tip:Always verify the shape of your tensors after each operation, especially when combining different components like positional encodings with embeddings. This practice can help identify and resolve many issues early in the development process.
The LayerNormalization module is a fundamental part of modern neural networks that stabilizes the activation distribution throughout the training process. Below is the detail of its structure and operations:
Constructor (__init__ method)
Initializes the layer normalization with an epsilon value eps for numerical stability:
eps (float, default: 1e-6): A small constant added to the standard deviation to prevent division by zero.
Inside the constructor:
self.alpha is a learnable scaling parameter, initialized to one. It’s responsible for scaling the normalized data.
self.bias is a learnable shifting parameter, initialized to zero. It allows the layer to shift the normalized data if needed.
Both self.alpha and self.bias are defined as nn.Parameter to indicate that they should be considered during the optimization process.
Forward Method (forward method)
The forward pass computes the mean and standard deviation across the last dimension of the input x.
It normalizes x by subtracting the mean and dividing by the standard deviation, which is offset by eps for numerical stability.
The learnable parameters self.alpha (often denoted as γ in literature) and self.bias (often denoted as β) are then applied to the normalized output.
This operation ensures that the activations have a mean of zero and a standard deviation of one, and then scales and shifts them as determined by the learned parameters.
Important Points:
self.alpha and self.bias are key to the layer’s ability to adaptively scale and shift the normalized data. This adaptability is crucial for the layer’s effectiveness in different contexts within the network.
The epsilon value eps adds stability to the normalization process, ensuring that the division by the standard deviation doesn’t lead to extremely large values when the standard deviation is very small.
The layer normalization process helps to reduce the internal covariate shift, which can significantly speed up training and lead to better overall performance.
Debugging Tip:
Keep an eye on the scale of self.alpha and the shift of self.bias as the training progresses. Unusual values in these parameters could indicate issues with data normalization or the learning rate.
The FeedForwardBlock module is an essential part of the Transformer architecture that performs feed-forward operations this is used in both encoder and decoder.
Here’s an overview of its setup and function:
Constructor (__init__ method)
The block is initialized with the following parameters:
d_model (int): The number of input and output features from the previous and next layers, respectively.
d_ff (int): The number of features in the hidden layer, typically larger than d_model.
dropout (float): The dropout rate to regulate the model’s complexity and prevent overfitting.
In the constructor:
self.linear_1 and self.linear_2 are fully connected layers that transform the input data.
A nn.Dropout layer is included to reduce the risk of overfitting by randomly setting a subset of activations to zero during training.
Forward Method (forward method)
The forward pass applies a linear transformation, followed by a ReLU activation function.
The dropout is applied after the activation function to the intermediate results.
Another linear transformation is applied to project the data back to the dimensionality of d_model.
Important Points:
The feedforward network consists of two linear transformations with a ReLU activation in between, which helps the network to learn complex mappings between inputs and outputs.
The dropout layer is essential for the network to generalize well and not just memorize the training data.
Debugging Tip:
Monitoring the output after the ReLU activation and before the final linear layer can provide insights into the health of the activations within the network. If most values are zeros, it might indicate dying ReLU problems.
The MultiHeadAttentionBlock plays a pivotal role in the transformer model, acting as the crux of the attention mechanism. This class encapsulates several key concepts:
Static Attention Method:
The attention function is defined as a staticmethod, highlighting a strategic design choice. This allows the method to be utilized across various components of the transformer, including both the encoder and decoder, without the necessity of an instance of the class.
It computes attention scores using the transformer’s original formula, scaling the dot product of queries and keys by the square root of the keys’ dimension (d_k).
Masking in Attention:
The method is designed to handle masking, essential for controlling attention flow, like ignoring padding tokens or maintaining causality in the decoder.
Dropout for Regularization:
Incorporating dropout within the attention mechanism aids in preventing overfitting, thus enhancing the model’s generalization capability.
Reshaping for Multi-Head Attention:
A distinctive feature of this implementation is the reshaping of the query (q), key (k), and value (v) into 4-dimensional tensors. This facilitates the multi-head attention mechanism, where the model concurrently processes the inputs through multiple attention ‘heads’.
This reshaping and transposition enable the model to focus on different aspects of the input sequence across various representation subspaces, a hallmark of the transformer’s architecture.
Usage in Transformer:
The multi-head attention mechanism is employed thrice in the transformer architecture – twice in the decoder and once in the encoder. This repeated usage underscores its significance in the model’s ability to process and interpret sequential data effectively.
Final Output Transformation:
Post attention computation and head concatenation, a final linear transformation through self.w_o aligns the output back to the original input dimension (d_model), a common practice in transformer models.
This class exemplifies the intricate and efficacious multi-head attention mechanism, pivotal to the transformer’s capacity for handling complex sequence-to-sequence tasks. The implementation of a static attention function, along with the strategy for multi-head attention via tensor reshaping, showcases the elegant and proficient design choices inherent in this model.
Residual Connection
classResidualConnection(nn.Module):
def__init__(self, dropout: float)->None:
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm =LayerNormalization()
defforward(self, x, sublayer):
return x +self.dropout(sublayer(self.norm(x)))
The ResidualConnection module is an integral component of the transformer architecture, playing a pivotal role in stabilizing and enhancing the training process. Let’s delve into its structure and functionality:
Constructor (__init__ method)
This method sets up the residual connection with a dropout rate:
dropout (float): Specifies the dropout rate, a technique used to prevent overfitting by randomly dropping units (neural network nodes) from the computation during training.
Inside the constructor:
The nn.Dropout layer is initialized with the specified dropout rate, providing a mechanism for regularizing the model.
A LayerNormalization layer is also instantiated, which normalizes the input layer by layer, ensuring that the network’s inputs are normalized in a consistent way. This helps in stabilizing the learning process.
Forward Method (forward method)
The forward pass of this module introduces the concept of a residual connection, which is a hallmark of the transformer architecture.
It takes two arguments:
x: The input to the residual connection.
sublayer: A function representing the sub-layer to be applied to the input. Typically, this could be an attention mechanism or a feed-forward network.
The input x is first normalized using the layer normalization (self.norm(x)), then passed through the sublayer.
The output of the sublayer undergoes dropout and is then added back to the original input x. This “residual” addition allows the gradients to flow directly through the network without being hindered by deep layers.
Important Points:
The residual connection (x + ...) plays a crucial role in enabling deep transformers to be trained effectively. It allows for direct paths for gradient flow during backpropagation, making it easier to train deeper models.
By applying layer normalization before the sublayer, the module ensures that the inputs to each sublayer are normalized, contributing to more stable and faster training.
The use of dropout within the residual connection further regularizes the model, preventing over-reliance on any single part of the network and promoting a more robust learning process.
The design of the ResidualConnection class exemplifies key principles in building deep learning architectures, like normalization, residual connections, and regularization, all crucial for training deep and effective models.
x =self.residual_connection[0](x,lambdax:self.self_attention_block(x,x,x, src_mask))
x =self.residual_connection[1](x,self.feed_forward_block)
return x
The EncoderBlock is a fundamental unit within the transformer’s encoder architecture. It encapsulates the mechanism of self-attention and feed-forward layers, essential for processing the input sequence. Here’s a breakdown of its structure and functionality:
Constructor (__init__ method)
The encoder block is initialized with key components of the transformer:
self_attention_block (MultiHeadAttentionBlock): Handles the self-attention mechanism, allowing the model to weigh the importance of different parts of the input sequence.
feed_forward_block (FeedForwardBlock): A feed-forward neural network that processes the output of the attention layer.
dropout (float): The dropout rate used for regularization.
Within the constructor:
The encoder block holds instances of the self_attention_block and feed_forward_block, representing the core functional units of the block.
self.residual_connection is a list of two ResidualConnection modules. These are used to implement the residual connections around the self-attention and feed-forward blocks, a key feature in the transformer architecture for efficient training and gradient flow.
Forward Method (forward method)
The forward pass of the encoder block involves two main steps:
Applying the self-attention mechanism to the input x with an optional source mask src_mask. The output then passes through the first residual connection.
Feeding the output of the first step through the feed-forward block, followed by the second residual connection.
In action:
The lambda function in the first residual connection allows for the application of the self-attention block to the normalized input.
The second residual connection wraps around the feed-forward block, ensuring the addition of the original input to the output of the feed-forward layer.
Important Points:
The EncoderBlock is designed to process each element in the input sequence while considering the entire sequence, a fundamental characteristic enabled by self-attention.
The use of residual connections around both the self-attention and feed-forward layers is crucial for the model’s deep learning capability, allowing gradients to flow through the network more effectively.
This class highlights the modular design of transformers, where each block is responsible for specific tasks (self-attention and feed-forward computation), and is combined in a manner that allows for complex sequence processing.
The EncoderBlock class embodies the principles of self-attention and feed-forward processing in a manner that is quintessential to the transformer’s ability to handle sequential data effectively.
Encoder
classEncoder(nn.Module):
def__init__(self, layers: nn.ModuleList) -> None:
super().__init__()
self.layers = layers
self.norm =LayerNormalization()
defforward(self,x, mask):
for layer inself.layers:
x =layer(x,mask)
returnself.norm(x)
The Encoder forms a central part of the transformer architecture, orchestrating the sequential application of multiple encoder layers to process the input sequence. Its implementation is straightforward yet crucial for the transformer’s functionality. Here’s an overview:
Constructor (__init__ method)
The encoder is initialized with a ModuleList of encoder layers:
layers (nn.ModuleList): A list of encoder layers (instances of EncoderBlock). This modular approach allows for flexibility in the number of layers and their composition.
In the constructor:
self.layers holds the series of encoder blocks that will process the input data sequentially.
self.norm is an instance of LayerNormalization, applied to the output of the last encoder layer for normalization.
Forward Method (forward method)
In the forward pass, the encoder iteratively processes the input x through each encoder layer in the self.layers list, using the provided mask:
The mask is typically used for masking out padding tokens in the input sequence.
Each layer in self.layers receives the input x and the mask, and its output is fed into the next layer in the sequence.
The significance of the loop:
The use of a for loop to iterate over the layers allows each layer to transform the input based on the output of the previous layer, enabling deep processing of the sequence.
This sequential processing is key to the encoder’s ability to build complex representations of the input data.
Post-Layer Normalization
After processing the input through all the encoder layers, the output undergoes layer normalization via self.norm. This step is crucial for stabilizing the output before it’s passed on to the next stage of the transformer model.
Important Points:
The Encoder serves as a pipeline, directing the input through a series of self-attention and feed-forward computations, each encapsulated within an EncoderBlock.
The modular design, with a ModuleList of EncoderBlocks, allows for custom configurations of the encoder, catering to different depths and complexities.
The final layer normalization is a vital step, ensuring that the encoder’s output is normalized and suitable for subsequent processing or for output generation.
In essence, the Encoder class demonstrates the transformer’s capacity for sequential data processing, showcasing the depth and complexity achievable through stacking multiple encoder layers.
x =self.residual_connections[0](x,lambdax: self.self_attention_block(x,x,x,tgt_mask))
x =self.residual_connections[1](x,lambdax: self.self_attention_block(x,encoder_output,encoder_output,src_mask))
x =self.residual_connections[2](x,self.feed_forward_block)
return x
The DecoderBlock is a vital component of the transformer’s decoder architecture. It integrates self-attention, cross-attention, and feed-forward networks, playing a critical role in processing and generating the output sequence. Here’s a breakdown of its structure and functionality:
Constructor (__init__ method)
The DecoderBlock is initialized with distinct elements for the decoding process:
self_attention_block (MultiHeadAttentionBlock): Handles the self-attention mechanism within the decoder, focusing on the positions up to and including the current position in the output sequence.
cross_attention_Block (MultiHeadAttentionBlock): Manages cross-attention, where the decoder attends to the encoder’s output.
feed_forward_block (FeedForwardBlock): A feed-forward neural network that processes the data after attention mechanisms.
dropout (float): The dropout rate for regularization.
Inside the constructor:
Three instances of ResidualConnection are created and stored in self.residual_connections. These wrap around each of the main components: the two attention blocks and the feed-forward block.
Forward Method (forward method)
The forward pass of the DecoderBlock takes four arguments:
x: The input to the decoder block.
encoder_output: The output from the encoder, used in cross-attention.
src_mask: The source mask for masking the encoder’s output.
tgt_mask: The target mask for masking the current decoder output.
Processing steps:
First, x passes through the self-attention mechanism with a target mask (tgt_mask). This is followed by the first residual connection.
Then, x is processed by the cross-attention block, attending to encoder_output with a source mask (src_mask). This goes through the second residual connection.
Finally, the output is fed through the feed-forward block and the last residual connection.
Important Points:
The sequential application of self-attention, cross-attention, and feed-forward networks allows the decoder to effectively generate each part of the output sequence by considering both its own previous outputs and the encoder’s output.
The use of residual connections around each component helps maintain the flow of gradients and preserves information throughout the depth of the decoder.
The DecoderBlock demonstrates the transformer’s ability to integrate information from the encoder while generating the output sequence, a key feature that enables its success in sequence-to-sequence tasks.
The design of the DecoderBlock reflects the sophisticated nature of the transformer model, where each component plays a specific role in processing the sequential data and generating accurate and coherent outputs.
The Decoder in the transformer architecture is crucial for generating the output sequence based on the encoded input. It is intricately designed to consider both the encoder’s output and its own output up to the current position. Here’s a detailed look:
Constructor (__init__ method)
The constructor initializes the Decoder with a ModuleList of DecoderBlock layers:
layers (nn.ModuleList): Contains a sequence of DecoderBlock instances. This allows the decoder to be composed of multiple layers, enhancing its ability to model complex relationships.
Inside the constructor:
self.layers holds the series of DecoderBlocks that process the input data sequentially.
self.norm is an instance of LayerNormalization, used to normalize the output of the last decoder layer.
Forward Method (forward method)
The forward pass of the decoder involves several key operations:
x: The current output sequence being generated.
encoder_output: The output from the encoder.
src_mask: A mask applied to the encoder output (useful for masking out padding tokens in source).
tgt_mask: A target mask that ensures the decoder only attends to earlier positions in the sequence, preventing it from seeing future tokens.
Processing steps:
The input x is passed through each DecoderBlock in the self.layers list, along with encoder_output, src_mask, and tgt_mask.
The for loop ensures each layer processes the sequence based on the output of the previous layer, allowing for deep sequential processing.
Important Points:
Masking in the Decoder/Decoder block: The target mask (tgt_mask) is essential in the decoder. It prevents the decoder from having information about the next word in the sequence, ensuring that each output token is generated based only on the previous tokens. This is crucial for tasks like language modeling and machine translation.
Residual Connections: Each DecoderBlock includes residual connections (similar to the encoder), facilitating the training of deep networks by allowing gradient flow.
Layer Normalization: After all decoder layers have processed the input, self.norm is applied, normalizing the output for consistent scale and variance.
The Decoder class encapsulates the transformer’s ability to generate coherent and contextually appropriate sequences by carefully combining self-attention with the context provided by the encoder’s output.
The ProjectionLayer in the Transformer model plays a crucial role in translating the high-dimensional output of the decoder into a probability distribution over the vocabulary. This layer is pivotal for tasks like language generation. Here’s an overview:
Constructor (__init__ method)
The ProjectionLayer is initialized with the following parameters:
d_model (int): The dimensionality of the input feature space, typically the same as the model’s internal representation size.
vocab_size (int): The size of the output vocabulary.
In the constructor:
self.proj is an instance of nn.Linear, which is a fully connected linear layer. It projects the input from the d_model-dimensional space to the vocab_size-dimensional space.
Forward Method (forward method)
The forward pass of the ProjectionLayer takes the input x and performs the following operations:
First, the input x is passed through the linear projection layer (self.proj(x)). This step transforms the input from the decoder’s output dimensionality to the vocabulary dimensionality.
Then, a logarithmic softmax function is applied to the output of the linear layer. This step converts the linear outputs into a log probability distribution over the vocabulary.
The significance of log softmax:
The use of the log softmax function is essential for transforming the raw output of the linear layer into a probability distribution.
Log softmax provides numerical stability compared to the regular softmax function, especially when dealing with large vocabularies or extreme values.
It computes the logarithm of the softmax function, which is useful for calculating the loss during training, especially in tasks like language modeling and machine translation.
Important Points:
The ProjectionLayer serves as the final step in the Transformer model’s output generation, converting the complex representations learned by the model into a format that directly corresponds to the probability of each word in the vocabulary.
This layer is crucial for tasks where the model needs to choose the next word or token, as it provides a clear and probabilistically interpretable output.
The transition from high-dimensional space to vocabulary space, followed by the application of log softmax, encapsulates the process of transforming abstract representations into concrete linguistic elements.
The ProjectionLayer exemplifies the Transformer’s capability to not only process and understand language but also to generate it in a probabilistically sound manner.
The Transformer class is the culmination of the various components of the Transformer model, orchestrating the entire sequence-to-sequence process. This class combines the encoder, decoder, embedding layers, positional encodings, and the projection layer into a cohesive unit. Here’s a detailed look:
Constructor (__init__ method)
The Transformer class is initialized with all the essential components of the transformer architecture:
encoder (Encoder): The encoder part of the transformer.
decoder (Decoder): The decoder part of the transformer.
src_embed and tgt_embed (InputEmbeddings): Embedding layers for the source and target sequences, respectively.
src_pos and tgt_pos (PositionalEncoding): Positional encoding layers for the source and target.
Projection_Layer (ProjectionLayer): The final projection layer that maps the decoder’s output to the output vocabulary.
In the constructor:
Each component is assigned to an instance variable, allowing the transformer to access and use these components in the encoding, decoding, and projection processes.
Encode Method (encode method)
Handles the encoding of the source sequence:
Applies the source embeddings and positional encoding to the input source sequence.
Passes the processed input through the encoder, along with a source mask if provided.
Decode Method (decode method)
Manages the decoding process based on the encoder’s output:
Applies target embeddings and positional encoding to the target sequence.
Processes the target sequence through the decoder, using the encoder output and both source and target masks.
Project Method (project method)
Applies the projection layer to the decoder’s output:
This function is typically used during inference to obtain the final output predictions.
Important Points:
The Transformer class effectively integrates the separate components into a unified model, showcasing the power of the transformer architecture in handling sequence-to-sequence tasks.
The encode-decode-project workflow encapsulates the transformer’s process: encoding the input, decoding for the target, and projecting the output to a usable format.
The separation of encode, decode, and project functions aligns with the model’s use during inference, where each step plays a distinct role in generating the final output.
This class is the heart of the Transformer model, tying together all the specialized components and enabling the model to perform complex tasks in natural language processing, such as machine translation and text generation.
The build_transformer function serves as a factory for creating a complete Transformer model. It integrates all the components we’ve discussed into a functional unit. Here’s an overview of its process:
Parameters:
Accepts various hyperparameters such as src_vocab_size, tgt_vocab_size, src_seq_len, tgt_seq_len, d_model, N (number of layers), h (number of heads in multi-head attention), dropout, and d_ff (dimension of feed-forward network).
Embedding Layers:
Initializes embedding layers for both the source (src_embed) and target (tgt_embed) sequences.
Positional Encoding Layers:
Creates positional encoding layers for both the source (src_pos) and target (tgt_pos) with dropout.
Encoder and Decoder Blocks:
Constructs multiple EncoderBlock and DecoderBlock instances, forming the core of the encoder and decoder respectively. The number of blocks is determined by the N parameter.
Assembly of Encoder and Decoder:
The encoder and decoder blocks are assembled into Encoder and Decoder modules using nn.ModuleList.
Projection Layer:
A ProjectionLayer is initialized to map the decoder’s output to the target vocabulary space.
Creation of Transformer Model:
The Transformer class is instantiated with the encoder, decoder, embeddings, positional encodings, and projection layer.
Parameter Initialization:
The model’s parameters are initialized using the Xavier uniform initialization method. This is a common practice for initializing neural network weights as it can help prevent vanishing or exploding gradients, especially in deep networks like the Transformer.
Final Notes:
This function encapsulates the entire process of building a Transformer model, demonstrating the modular nature of its architecture.
With the model now built, the next steps involve training it on a specific task (like translation or text generation) and then using it for inference.
By the end of this function, we have a fully assembled Transformer model, ready for training and subsequent inference tasks.