Self-Attention
Single Headed
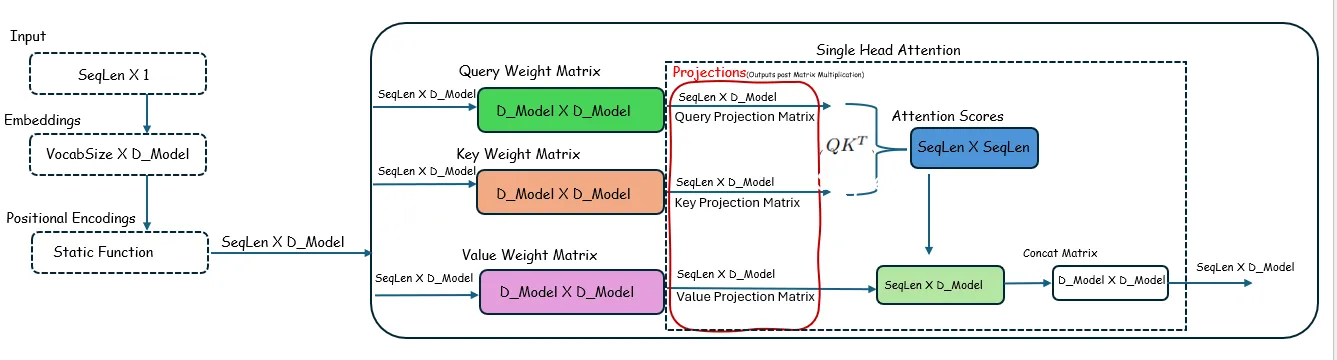
- Ignore the Softmax operation and normalize by dividing by the square root of
d_model, because these operations do not affect the dimensions of the matrices involved.
Multiheaded
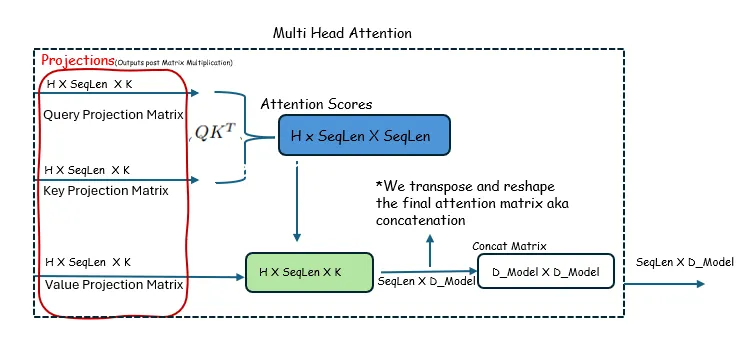
- Ignore the Softmax operation and normalize by dividing by the square root of
d_model, because these operations do not affect the dimensions of the matrices involved.