- Step-by-step coding tutorials for building Transformer models.
- Insights into the inner workings of different Transformer components.
- Practical examples and code snippets to illustrate concepts.
Implementing transformers
A Practical Guide
Welcome to our specialized blog section, where we turn the theory of Transformers into tangible code. Here, we’re not just discussing concepts; we’re building them.
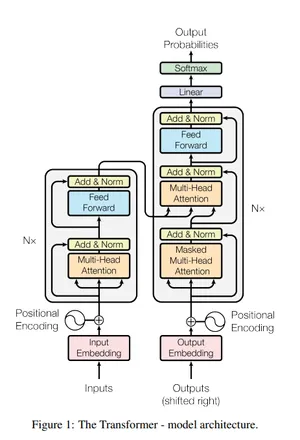
In this series, we embark on a hands-on journey to implement the key ideas presented in the “Attention is All You Need” paper. Our goal is to transform theoretical knowledge into practical skills, focusing on the actual coding of Transformers and their derivatives.
Coding Transformers: Step-by-Step
Transformers are more than a concept; they are a toolkit for revolutionizing data processing in AI. This section will provide:
Advanced Implementations: BERT, GPT, and Beyond
Once we have a solid foundation, we’ll dive into more complex architectures derived from Transformers, such as BERT and GPT. In this advanced section, you will:
- Explore the specific coding nuances of each architecture.
- Implement these models from scratch.
- Learn how to adapt and extend these models for custom applications.
Get ready to roll up your sleeves and code! Our first post will guide you through setting up your development environment and coding your first Transformer model. Let’s turn theory into practice together!